Linux Administration for DBA’s: Checking Disk Space
Problem
With the 2016 release of SQL Server, Microsoft has decided to expand SQL Server operating systems to Linux servers. Since most of the SQL Server administrators are not familiar working with Linux, you may not know how to check for disk space usage. In this tip I will show you how to check file sizes and disk space usage when using SQL Server on Linux.
Solution
When working with Linux, most of the time you will have to use a remote shell connection. That's because nobody installs the GUI on production servers due to the fact that on Linux you can do everything from the console.
The ls Command
This command, according to the manual page (
man ls), lists directory contents, just like the
dir command on Windows. But there are some peculiarities that may confuse Windows users. For instance, if you run
ls without any argument it just returns a list of archives without information of the file size, like when you run
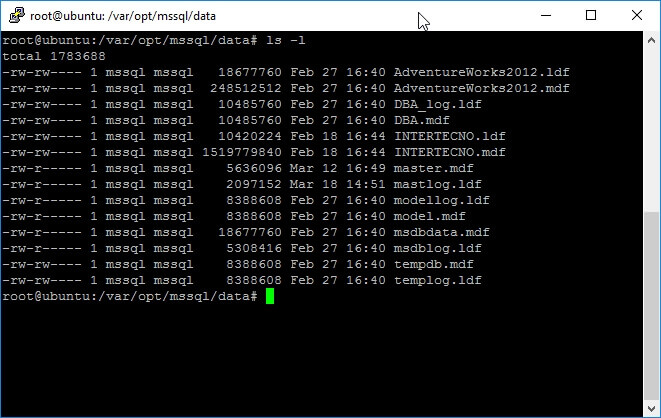
dir /w on Windows. In order to get a full list of files you should run the ls command with the -l argument as shown below.
The next image is a screen capture of the previous command execution. We can see that on the first line this command informs the total size of the files being listed and the rest of the output is a grid that shows information about each file.
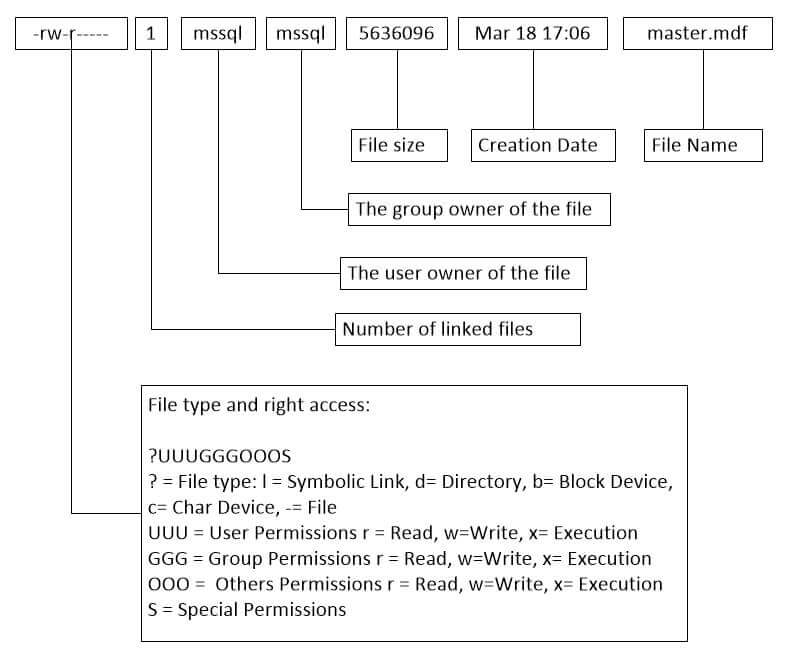
On the following chart I explain what each column of the grid is for.
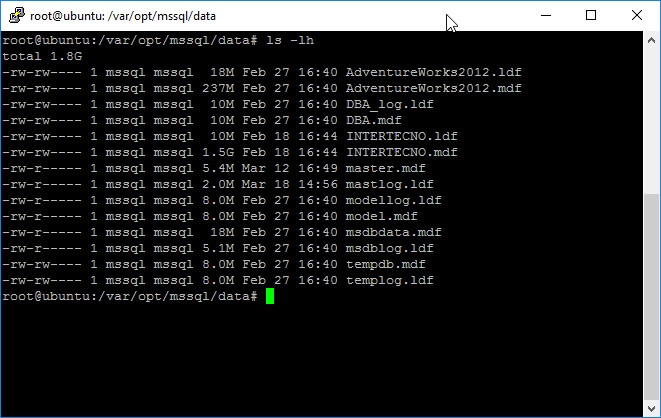
As you may have noticed, the file size is expressed in bytes, but for large database files this is useless, so we need to view the file sizes in an easier to read format. For this, adding the h argument will do the work as follows.
The df Command
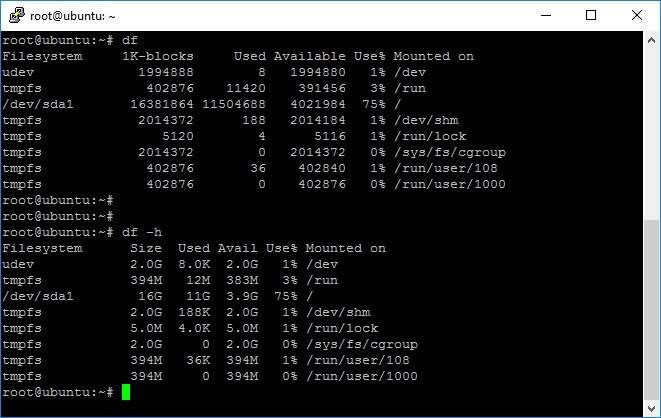
This command displays the used and available disk space and the mounting point of the file systems.
To get the full list of available options I suggest you read the
df Manual Page.
To make the output easier to read for the file sizes, we will use –h to print the results in MB, GB and so on.
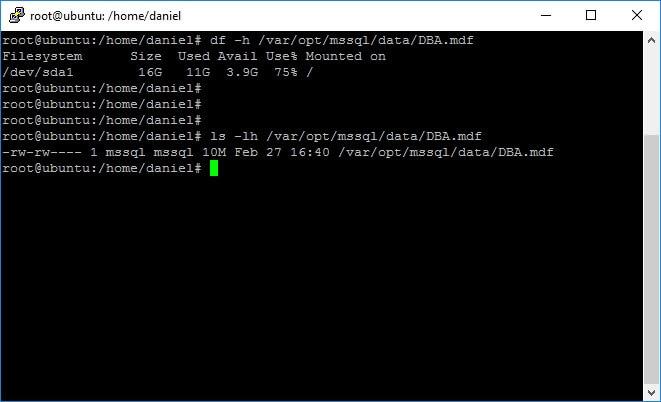
You can also pass as an argument a file name or a directory and it tells you the used and available free space on the underlying disk. Please note on the next screen capture that I executed the
df command passing a file argument and the used space reported by
df, which is the used drive space. This differs from the file size reported by the
ls command.
df -h /var/opt/mssql/data/DBA.mdf
The du Command
The
du (i.e. disk usage) command shows the size of a given directory tree and its subfolders and files (if you use the
* or
–a switch). Something to note is that you need to have read permission on the folders and files in order to get their size, so if you are looking only for a file size I would suggest using
ls –l instead.
When
du is executed with de
–a switch it returns the size of all files and folders, even the hidden ones (those whose name starts with a dot “.”) that are not displayed with the
* argument. The
du command also accepts the
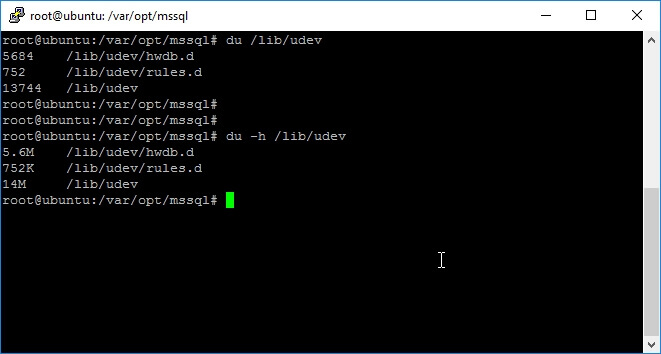
–h switch to display the results in human readable form, which is much easier to read. The next screen capture shows the execution of
du with and without
-h parameter.
du /lib/udev
du -h /lib/udev
Something to note is that we can use pipes (the
| character) to redirect the output of one command to another. We can take advantage of this feature to sort the output of the
du command by sending its content to the
sort command. The following code shows how to sort the output of
du. The
–n switch of the
sort command is to let the
sort command know that we want a numeric sort and not a character one.
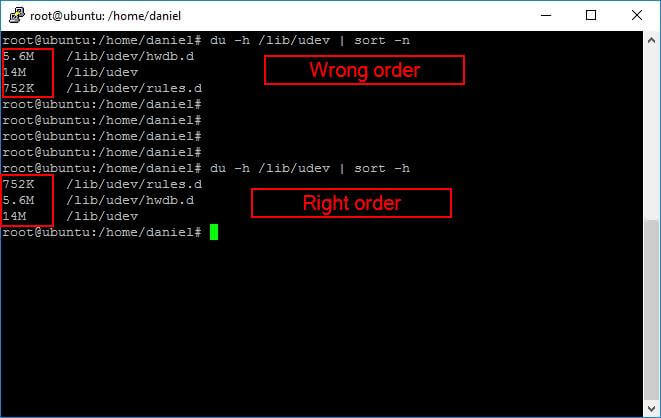
But if you use the
–h switch of du command and want to order its output as a numeric sort like in the following code, you may have bogus results.
This must not surprise you, because even when the command
du –h returns a number on its first column, that number carries an underlying size measure unit (GB, MB and so on). So we must change the sort command a little bit: instead of the
–n switch we must use the
–h switch, and yes, the
-h is for human readable.
In the following screen capture I show you the difference of piping the
du –h command with those variants of the sort command.
du -h /lib/udev | sort –n
du -h /lib/udev | sort –h