Getting exclusive access to restore SQL Server databases
Problem
A task that you may be faced with as a DBA is the need to refresh a test or development database on a periodic basis. This may be a scheduled process or it may be an ad hoc process. One of the things that you need to do when restoring a database is to ensure you have exclusive access to the database otherwise the restore process will not work. What options are there to ensure you have exclusive database access, so the restore process will work without issue?Solution
There are a couple of options that you have to ensure that you have exclusive access to the database. The following outlines a few of these options and how this task can be simplified.Kill Users
For this option to work you need to ensure that once you kill the connection, that the connection doesn't reconnect. In some systems where you have automated connections occurring, this may not be the best option. Take a look at this prior tip, Die Sucker - Killing SQL Server Process Ids (spids).Using GUI to do restore
In Enterprise Manager and SQL Server Management Studio there is not an option to kill all of the users when restoring a database. You can go through the restore steps, but if you click on restore the process will start, but it will not complete. Eventually it will time out and you will get an error message like this: So this is not an option if you have open transactions and connections to the database.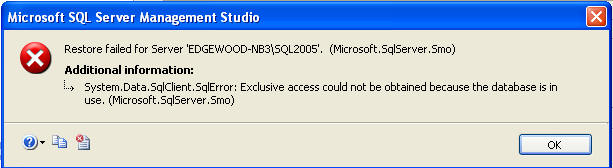
Detach Database, Reattach and Restore
Another possible approach would be to detach the database. When doing this through the GUI you have the option of dropping existing connections first. The way this is done is that the existing connections are killed first, the database is put into single user mode and then the database is taken offline.With this method you could detach with drop connections, reattach the database, put the database is single user mode and then do the restore, but there is still a chance that a connection could be made and you would be back in the same spot. So this is not really a good option either, plus there are too many steps.
ALTER DATABASE
The best approach for doing this would be to use the ALTER DATABASE command to set the database to single user mode along with rolling back any open transactions. The command looks something like one of the following.ALTER DATABASE [Test4] SET SINGLE_USER WITH ROLLBACK IMMEDIATE OR ALTER DATABASE [Test4] SET SINGLE_USER WITH ROLLBACK AFTER 30 OR ALTER DATABASE [Test4] SET SINGLE_USER WITH NO_WAIT
- WITH ROLLBACK IMMEDIATE - this option doesn't wait for transactions to complete it just begins rolling back all open transactions
- WITH ROLLBACK AFTER nnn - this option will rollback all open transactions after waiting nnn seconds for the open transactions to complete. In our example we are specifying that the process should wait 30 seconds before rolling back any open transactions.
- WITH NO_WAIT - this option will only set the database to single user mode if all transactions have been completed. It waits for a specified period of time and if the transactions are not complete the process will fail. This is the cleanest approach, because it doesn't rollback any transactions, but it will not always work if there are open transactions.
Note: when using the ROLLBACK option you are rolling back any open transactions that still exist for the database. The rollback process should work without issue, but if you have very long running transactions the rollback process could take a long time, so be aware of what is running on your systems. For test and development systems since you are doing a restore you don't care about the transactions anyway, so rolling things back should not be an issue, but you still need to be aware that long running transactions may take some time to rollback.
Summary
Once the database is in single user mode it is now easy to perform the restore process. Here is a sample set of code that puts the database in single user mode and does the restore.ALTER DATABASE [Test4] SET SINGLE_USER WITH ROLLBACK IMMEDIATE RESTORE DATABASE [Test4] FROM DISK = 'c:\test4.BAK' WITH MOVE 'Test4_Data' TO 'c:\data\Test4.mdf', MOVE 'Test4_Log' TO 'c:\data\Test4_log.ldf'
ALTER DATABASE [Test4] SET MULTI_USER